
An effective approach for determining sample size that optimizes the performance of classifier
determining sample size that optimizes the performance of classifier
Keywords:
: Learning curve, model optimization, random forest, effective sample sizeAbstract
The goal of machine learning is to create a model that performs well and gives accurate prediction outcome in a particular set of
classification tasks. In order to achieve higher performance, machine-learning model has to be optimized. Literature shows that parameter
and hyper-parameter tuning is most widely used for model optimization. In most classification tasks, the dataset is divided into training
and testing set with 70% and 30% for training and test respectively. However, the 70% training and 30% testing set division does not
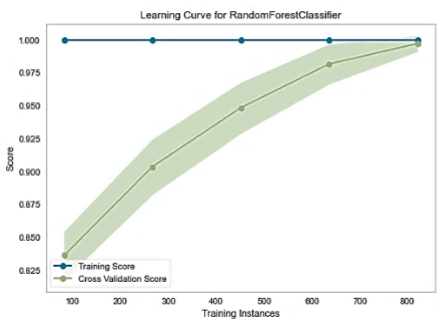
grantee better predictive outcome for all classification. Thus, this study proposes learning curve for analysis of the effect of data size on
the performance of classification model using real world heart disease dataset employing random forest model. The experimental result
shows that data sample size has significant effect on the performance of random forest model. Learning curve is the best approach for
determining the sample size for classification task using machine-learning model.
Downloads
References
decision tree classification: a machine learning approach,”
International Journal of Electrical and Computer Engineering., Vol. 9,
No. 5, October 2019, Art. no. pp. 4446~4451.
[2] T.A Assegie, R.L Tulasi, N.K Kumar, “Breast cancer prediction model
with decision tree and adaptive boosting,” IAES International Journal
of Artificial Intelligence, Vol. 10, No. 1, March 2021, Art. no. pp.
184~190.
[3] X. Chen, “Coronary Artery Disease Detection by Machine Learning with
Coronary Bifurcation Features, “Appl. Sci. 2020, 10, 7656; doi:
10.3390/app10217656.
[4] P. Sujatha and K. Mahalakshmi, “Performance Evaluation of
Supervised Machine Learning Algorithms in Prediction of Heart
disease,” 2020 IEEE International Conference for Innovation in
Technology, Nov 6-8, 2020.
[5] T.N Nguyen, “Multi-class Support Vector Machine Algorithm for Heart
Disease Classification”, International Conference on Green
Technology and Sustainable Development, 2020.
[6] M. Benllarch, “Improve Extremely Fast Decision Tree Performance
through Training Dataset Size for Early Prediction of Heart Diseases”,
IEEE, 2019.
[7] F. Tasnim, S.U Habiba, “A Comparative Study on Heart Disease
Prediction Using Data Mining Techniques and Feature Selection”,
International Conference on Robotics, Electrical and Signal
Processing Techniques, IEEE, 2021.
[8] Ni. Gupta, “Intelligent heart disease prediction in cloud environment
through ensembling”, Expert Systems,
https://doi.org/10.1111/exsy.12207, 2017.
[9] R.G. Franklin, “Survey of Heart Disease Prediction and Identification
using Machine Learning Approaches”, Proceedings of the Third
International Conference on Intelligent Sustainable Systems, 2020.
[10]R.L Fueroa, Q.Z Treitler, S. Kndula and L.H Ngo, “Predicting sample
size required for classification performance”, BMC Medical
Informatics and Decision Making 2012, 12:8.
[11]T.A Assegie, R. L Tulasi, N.K Kumar, “Breast cancer prediction model
with decision tree and adaptive boosting”, IAES International Journal
of Artificial Intelligence, Vol. 10, No. 1, March 2021, pp. 184-190.
[12] K.M Almustafa, “Prediction of heart disease and classifiers’ sensitivity
analysis”, BMC, Bioinformatics, 2020, 21:278
https://doi.org/10.1186/s12859-020-03626-y
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2022 Tsehay Admassu Assegie

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
All papers should be submitted electronically. All submitted manuscripts must be original work that is not under submission at another journal or under consideration for publication in another form, such as a monograph or chapter of a book. Authors of submitted papers are obligated not to submit their paper for publication elsewhere until an editorial decision is rendered on their submission. Further, authors of accepted papers are prohibited from publishing the results in other publications that appear before the paper is published in the Journal unless they receive approval for doing so from the Editor-In-Chief.
IJISAE open access articles are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. This license lets the audience to give appropriate credit, provide a link to the license, and indicate if changes were made and if they remix, transform, or build upon the material, they must distribute contributions under the same license as the original.



