
BERT based Hierarchical Alternating Co-Attention Visual Question Answering using Bottom-Up Features
Keywords:
VQA, Visual-Question Answering, BERT-based VQA, Hierarchical VQA, Image Question answeringAbstract
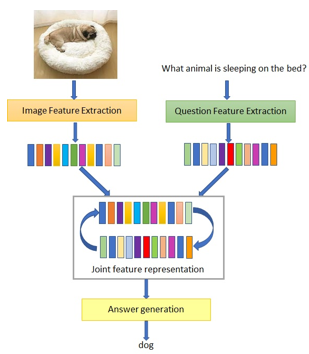
Answering a question from a given visual image is a very well-known vision language task where the machine is given a pair of an image and a related question and the task is to generate the natural language answer. Humans can easily relate image content with a given question and reason about how to generate an answer. But automation of this task is challenging as it involves many computer vision and NLP tasks. Most of the literature focus on a novel attention mechanism for joining image and question features ignoring the importance of improving the question feature extraction module. Transformers have changed the way spatial and temporal data is processed. This paper exploits the power of Bidirectional Encoder Representation from Transformer (BERT) as a powerful question feature extractor for the VQA model. A novel method of extracting question features by combining output features from four consecutive encoders of BERT has been proposed. This is from the fact that each encoder layer of the transformer attends to features from the word to a phrase and ultimately to a sentence-level representation. A novel BERT-based hierarchical alternating co-attention VQA using the Bottom-up features model has been proposed. Our model is evaluated on the publicly available benchmark dataset VQA v2.0 and experimental results prove that the model improves upon two baseline models by 9.37% and 0.74% respectively.
Downloads
References
S. Antol , A. Agrawal , J. Lu , M. Mitchell , D. Batra , C.L. Zitnick , D. Parikh ,” VQA: visual question answering”, Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 2425–2433. doi: 10.1109/ICCV.2015.279.
N. Ruwa, Q. Mao, L. Wang and M. Dong, "Affective Visual Question Answering Network," IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), 2018, pp. 170-173, doi: 10.1109/MIPR.2018.00038.
Z. Yang, X. He, J. Gao, L. Deng and A. Smola, "Stacked Attention Networks for Image Question Answering," IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 21-29, doi: 10.1109/CVPR.2016.10.
H. Noh, P. H. Seo and B. Han, "Image Question Answering Using Convolutional Neural Network with Dynamic Parameter Prediction," IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 30-38, doi: 10.1109/CVPR.2016.11.
Ilija Ilievski, Shuicheng Yan, Jiashi Feng,”A Focused Dynamic Attention model for visual question answering.'' [Online]. Available: https://arxiv.org/abs/-1604.01485 (2016).
K. Kafle and C. Kanan, "Answer-Type Prediction for Visual Question Answering," IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 4976-4984, doi: 10.1109/CVPR.2016.538.
Nguyen D. and Okatani T., "Improved Fusion of Visual and Language Representations by Dense Symmetric Co-attention for Visual Question Answering," IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 6087-6096 (2018).
M. Malinowski, M. Rohrbach and M. Fritz, "Ask Your Neurons: A Neural-Based Approach to Answering Questions about Images," IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1-9, doi: 10.1109/ICCV.2015.9.
Haoyuan gao, Junhua Mao, Jie Zhou, Zhiheng Huang, Lei Wang, and Wei Xu. ,” Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering”, Proc. Advances in Neural Inf. Process. Syst., 2015.
Bolei Zhou, Yuandong Tian, Sainbayar Sukhbaatar, Arthur Szlam, and Rob Fergus,” Simple baseline for visual question answering”, [online] Available: arXiv preprint arXiv:1512.02167, 2015.
Xu, H., Saenko, K. , ”Ask, Attend and Answer: Exploring Question-Guided Spatial Attention for Visual Question Answering” Computer Vision – ECCV 2016. Lecture Notes in Computer Science, vol. 9911. Springer, Cham. https://doi.org/10.1007/978-3-319-46478-7_28
Gupta D., Lenka P., Ekbal Asif, Bhattacharya P., “A Unified Framework for Multilingual and Code-Mixed Visual Question Answering” , Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing (pp. 900–913). Association for Computational Linguistics (2020).
Yang C., Jiang M., Jiang B., Zhou W. and Li K., "Co-Attention Network With Question Type for Visual Question Answering," in IEEE Access, vol. 7, pp. 40771-40781,201 (2019).
Zhou Yu, Jun Yu, Jianping Fan, and Dacheng Tao. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. In ICCV, pages 1839–1848, 2017
Pan Lu, Hongsheng Li, Wei Zhang, Jianyong Wang, and Xiaogang Wang. “Co-attending free-form regions and detections with multi-modal multiplicative feature embedding for visual question answering”, In Proceedings of the AAAI Conference on Artificial Intelligence, 2018, pp 7218-7225.
Peng Wang, Qi Wu, Chunhua Shen, Anthony R. Dick, and Anton van den Hengel, “ Explicit knowledge-based reasoning for visual question answering”, IJCAI, pages 1290–1296, 2017.
Jin-Hwa Kim, Jaehyun Jun, & Byoung-Tak Zhang,”Bilinear Attention Networks, 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, Canada. CoRR, abs/1805.07932.
Lianli Gao, Liangfu Cao, Xing Xu, Jie Shao, Jingkuan Song,”Question-Led object attention for visual question answering,Neurocomputing,Volume 391,2020,Pages 227-233,ISSN 0925-2312
Deepak Gupta, Pabitra Lenka, Asif Ekbal, and Pushpak Bhattacharyya,” A Unified Framework for Multilingual and Code-Mixed Visual Question Answering”,. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, pages 900–913, Suzhou, China. Association for Computational Linguistics.
Attention Is All You Need, 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
K. J. Shih, S. Singh and D. Hoiem, "Where to Look: Focus Regions for Visual Question Answering," IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 4613-4621, doi: 10.1109/CVPR.2016.499.
R. Burt, M. Cudic and J. C. Principe, "Fusing attention with visual question answering," 2017 International Joint Conference on Neural Networks (IJCNN), 2017, pp. 949-953, doi: 10.1109/IJCNN.2017.7965954.
Nguyen, Kien & Okatani, Takayuki. (2018). Improved Fusion of Visual and Language Representations by Dense Symmetric Co-attention for Visual Question Answering. 6087-6096. 10.1109/CVPR.2018.00637.
Lu J., Yang J., Batra D., and Parikh D., “Hierarchical question image co-attention for visual question answering,'' in Proc. NIPS, 2016, pp. 289_297 (2016).
G. Gu, S. T. Kim and Y. M. Ro, "Adaptive attention fusion network for visual question answering," IEEE International Conference on Multimedia and Expo (ICME), 2017, pp. 997-1002, doi: 10.1109/ICME.2017.8019540.
Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach,”Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding”, Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 457–468, Austin, Texas. Association for Computational Linguistics.
M. Dias, H. Aloj, N. Ninan and D. Koshti, "BERT based Multiple Parallel Co-attention Model for Visual Question Answering," 2022 6th International Conference on Intelligent Computing and Control Systems (ICICCS), 2022, pp. 1531-1537, doi: 10.1109/ICICCS53718.2022.9788253.
P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, L. Zhang,” Bottom-up and top-down attention for image captioning and VQA”, arXiv: 1707. 07998 (2017).
Zhou Yu, Jun Yu, Yuhao Cui, Dacheng Tao, Qi Tian,” Deep Modular Co-Attention Networks for Visual Question Answering”Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 6281-6290
Y. Goyal , T. Khot , D. Summers-Stay , D. Batra , D. Parikh , “Making the V in VQA matter :Elevating the role of image understanding in visual question answer- ing”, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6325–6334 .
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
All papers should be submitted electronically. All submitted manuscripts must be original work that is not under submission at another journal or under consideration for publication in another form, such as a monograph or chapter of a book. Authors of submitted papers are obligated not to submit their paper for publication elsewhere until an editorial decision is rendered on their submission. Further, authors of accepted papers are prohibited from publishing the results in other publications that appear before the paper is published in the Journal unless they receive approval for doing so from the Editor-In-Chief.
IJISAE open access articles are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. This license lets the audience to give appropriate credit, provide a link to the license, and indicate if changes were made and if they remix, transform, or build upon the material, they must distribute contributions under the same license as the original.



