
Performance Analysis for ROUGE And F-Measure in Arabic Text Summarization
Keywords:
Arabic Language, text summarization, ROUGE, F-measure, preprocessingAbstract
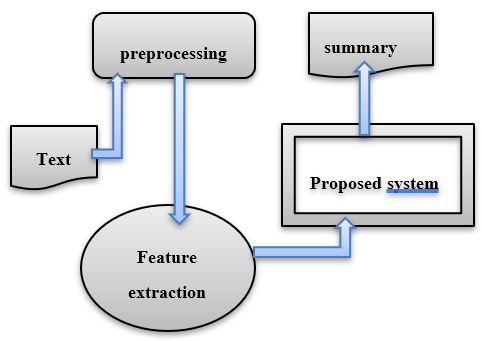
Summarizing a document has become a necessity as, because so much information is produced every day. Document summary makes it simpler to understand the text document than it would be to read through a collection of documents. A foundation for creating an condensed version of one or more text documents is provided by text summary. It is a crucial method for finding pertinent information on the Internet or in sizable text libraries. Additionally, it is essential to extract data in a way that the user would find the information interesting. Extractive summarization and abstract summarization are the two basic approaches used for text summarizing. In order to create the summary, the extractive summarization method chooses the sentences from a Word document and arranges them according to their weight. Abstractive summarizing is a technique that takes the key ideas from a document's content and expresses them abstractly in plain English. Numerous summary methods have been created on the foundation of these two approaches. There are numerous techniques that are language-specific exclusively. In this paper, we used extractive summarization methods and got good results.
Downloads
References
S. Pawar, & S. Rathod, (2020). Text summarization using cosine similarity and clustering approach (No. 2927). EasyChair.
A. Haboush , M. Al-Zoubi, A. Momani, & M. Tarazi, (2012). Arabic text summarization model using clustering techniques. World of Computer Science and Information Technology Journal (WCSIT) ISSN, 2221-0741.
N. J. Kadhim, & Saleh, H. H. (2018). Improving Extractive Multi-Document Text Summarization Through Multi-Objective Optimization. Iraqi Journal of Science, 2135-2149.
A. Qaroush , I. A. Farha, W. Ghanem, M. Washaha &E. Maali (2019). An efficient single document Arabic text summarization using a combination of statistical and semantic features. Journal of King Saud University-Computer and Information Sciences.
L. Al Qassem, D. Wang, H. Barada, A. Al-Rubaie, & Almoosa, N. (2019, September). Automatic Arabic text summarization based on fuzzy logic. In Proceedings of the 3rd international conference on natural language and speech processing (pp. 42-48).
Q. A. Al-Radaideh, & D. Q. Bataineh (2018). A hybrid approach for arabic text summarization using domain knowledge and genetic algorithms. Cognitive Computation, 10(4), 651-669.
R. Belkebir & A. Guessoum, (2015). A supervised approach to arabic text summarization using adaboost. In New contributions in information systems and technologies (pp. 227-236). Springer, Cham.
M. Attia, (2007, June). Arabic tokenization system. In Proceedings of the 2007 workshop on computational approaches to semitic languages: Common issues and resources (pp. 65-72).
L. S. Larkey, L. Ballesteros & M. E. Connell (2007). Light stemming for Arabic information retrieval. In Arabic computational morphology (pp. 221-243). Springer, Dordrecht.
F. Rahutomo, T. Kitasuka, & M. Aritsugi, (2012). Semantic Cosine Similarity. In The 7th International Student Conference on Advanced Science and Technology ICAST.
D. Wali,, &N. Modhe, (2015). Word Sense Disambiguation Algorithms in Hindi.
V. Siivola,, & M. L. Pellom,. (2005). Growing an n-gram language model. In Ninth European conference on speech communication and technology.
F. T .AL-Khawaldeh, & V. W. Samawi, (2015). Lexical cohesion and entailment based segmentation for arabic text summarization (lceas). World of Computer Science & Information Technology Journal, 5(3).
W. Kryscinski, R. Paulus, C. Xiong, &R. Socher, (2018). Improving abstraction in text summarization. arXiv preprint arXiv:1808.07913.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
All papers should be submitted electronically. All submitted manuscripts must be original work that is not under submission at another journal or under consideration for publication in another form, such as a monograph or chapter of a book. Authors of submitted papers are obligated not to submit their paper for publication elsewhere until an editorial decision is rendered on their submission. Further, authors of accepted papers are prohibited from publishing the results in other publications that appear before the paper is published in the Journal unless they receive approval for doing so from the Editor-In-Chief.
IJISAE open access articles are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. This license lets the audience to give appropriate credit, provide a link to the license, and indicate if changes were made and if they remix, transform, or build upon the material, they must distribute contributions under the same license as the original.



