
Adaptive Fault-Tolerance During Job Scheduling in Cloud Services Based on Swarm Intelligence and Apache Spark
Keywords:
Fault-tolerance, Job Scheduling, Cloud services, Apache SparkAbstract
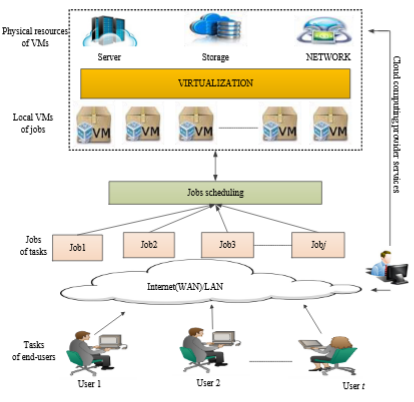
Cloud services are generally seen as a promising technique developed to achieve the highest computation service needs. However, such high-performing level of computing services can lead to the highest level of failure rates owing to a wide range of components and host servers which are filled with intensive job scheduling problems. Therefore, failure which occurs in one component or sub-system will lead to the unavailability of the computation services for the system. In this research, we suggest a new effective model called adapting fault-tolerant model (AFTM) which aimed to examine the optimization of job scheduling problem in computing infrastructure based on Particle Swarm Optimization (PSO), Apache Sparka and Ant Colony Optimization (ACO). The proposed approach covers the implementation and analysis of virtualizations with the job task selection to health monitoring for fault diagnoses based on Apache Spark. The objective is to find the cost trade-off between the allocated memory and CPU execution time required by virtualization services created by the end-users. The evaluation of the empirical performance of the proposed approach results outperforms PSO algorithms and traditional Genetic Algorithm (GA) in terms of the allocated memory and the time of CPU execution.
Downloads
References
TYAGI, Rinki; GUPTA, Santosh Kumar. A Survey on Scheduling Algorithms for Parallel and Distributed Systems. In: Silicon Photonics & High Performance Computing. Springer, Singapore, 2018. p. 51-64.
PRAKASH, Shiva, et al. A Literature Review of QoS with Load Balancing in Cloud Computing Environment. In: Big Data Analytics. Springer, Singapore, 2018. p. 667-675.
Kalanirinika GR, et al.” fault tolerance in cloud using reactive and proactive techniques”.
Alkasem, A., Liu, H., Zuo, D., & Algarash, B. (2018). Cloud Computing: A model Construct of Real-Time Monitoring for Big Dataset Analytics Using Apache Spark. In Journal of Physics: Conference Series (Vol. 933, No. 1, p. 012018). IOP Publishing..
Ameen Alkasem, Hongwei Liu and Decheng Zuo. CloudPT Performance Testing for Identifying and Eliminating Bottlenecks in Dynamic Cloud Services[C]. 18th International Conference on Algorithms and Architectures for Parallel Processing (ICA3PP), 2018.
Egwutuoha, I.P., Chen, S., Levy, D., Selic, B. and Calvo, R., 2012, November. A proactive fault tolerance approach to High Performance Computing (HPC) in the cloud. In Cloud and Green Computing (CGC), 2012 Second International Conference on (pp. 268-273). IEEE.
Jhawar, R., Piuri, V. and Santambrogio, M., 2013. Fault tolerance management in cloud computing: A system-level perspective. IEEE Systems Journal, 7(2), pp.288-297.
Hwang, S. and Kesselman, C., 2003. A flexible framework for fault tolerance in the grid. Journal of Grid Computing, 1(3), pp.251-272.
Patra PK, Singh H, Singh G (2013) Fault tolerance techniques and comparative implementation in cloud computing. Int J Comput Appl 64(14):37–41.
Nawi NM, Khan A, Rehman M, Chiroma H, Herawan T (2015) Weight optimization in recurrent neural networks with hybrid metaheuristic Cuckoo search techniques for data classification. Math Probl Eng 501:868375.
Xu H, Yang B, Qi W, Ahene E (2016) A multi-objective optimization approach to workflow scheduling in clouds considering fault recovery. KSII Trans Internet Inf Syst 10(3):976–995. doi:10.3837/tiis.2016.03.002.
Kumar VS, Aramudhan M (2014) Hybrid optimized list scheduling and trust based resource selection in cloud computing. J Theor Appl Inf Technol 69(3):434–442
Gcacasior J, Seredyński F (2013) Multi-objective parallel machines scheduling for fault-tolerant cloud systems. In: Joanna K, Di Martino B, Talia D, Xiong K (eds) Algorithms and architectures for parallel processing. Springer, Switzerland, pp 247–256. doi:10.1007/978-3-319-03859-9_21
Kaveh A (2014) Particle swarm optimization. In: Advances in metaheuristic algorithms for optimal design of structures. Springer, Switzerland, pp 9–40. doi:10.1007/978-3-319-05549-7
Yuan H, Li C, Du M (2014) Optimal virtual machine resources scheduling based on improved particle swarm optimization in cloud computing. J Softw 9(3):705–708
Kaur, J., Kalra, A., & Sharma, D. (2018). Comparative Survey of Swarm Intelligence Optimization Approaches for ANN Optimization. In Intelligent Communication, Control and Devices(pp. 305-314). Springer, Singapore.
Lin, F. P. C., & Phoa, F. K. H. (2018). An efficient construction of confidence regions via swarm intelligence and its application in target localization. IEEE Access, 6, 8610-8618.
Chu, S. C., Huang, H. C., Roddick, J. F., & Pan, J. S. (2011, September). Overview of algorithms for swarm intelligence. In International Conference on Computational Collective Intelligence(pp. 28-41). Springer, Berlin, Heidelberg.
Zhang, X., & Zhang, X. (2017). Thinning of antenna array via adaptive memetic particle swarm optimization. EURASIP Journal on Wireless Communications and Networking, 2017(1), 183.
https://en.wikipedia.org/wiki/Ant_colony_optimization_algorithms
Ameen Alkasem, Hongwei Liu, Muhammad Shafiq, and Decheng Zuo, "A New Theoretical Approach: A Model Construct for Fault Troubleshooting in Cloud Computing," Mobile Information Systems, vol. 2017, Article ID 9038634, 16 pages, 2017. doi:10.1155/2017/9038634.
Salloum, S., Dautov, R., Chen, X., Peng, P. X., & Huang, J. Z. (2016). Big data analytics on Apache Spark. International Journal of Data Science and Analytics, 1(3-4), 145-164.
Mavridis, I., & Karatza, H. (2017). Performance evaluation of cloud-based log file analysis with Apache Hadoop and Apache Spark. Journal of Systems and Software, 125, 133-151.
Ameen Alkasem, Hongwei Liu, and Decheng Zuo. "Utility Cloud: A Novel Approach for Diagnosis and Self-healing Based on the Uncertainty in Anomalous Metrics." In Proceedings of the 2017 International Conference on Management Engineering, Software Engineering and Service Sciences (ICMSS '17), Yulin Wang (Ed.). ACM,NewYork,NY,USA,99-107.DOI: https://doi.org/10.1145/3034950.3034967, (2017).
Vasconcelos, P. R. M., & de Araújo Freitas, G. A. (2014, December). Performance analysis of Hadoop MapReduce on an OpenNebula cloud with KVM and OpenVZ virtualizations. In Internet Technology and Secured Transactions (ICITST), 2014 9th International Conference for (pp. 471-476). IEEE.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
All papers should be submitted electronically. All submitted manuscripts must be original work that is not under submission at another journal or under consideration for publication in another form, such as a monograph or chapter of a book. Authors of submitted papers are obligated not to submit their paper for publication elsewhere until an editorial decision is rendered on their submission. Further, authors of accepted papers are prohibited from publishing the results in other publications that appear before the paper is published in the Journal unless they receive approval for doing so from the Editor-In-Chief.
IJISAE open access articles are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. This license lets the audience to give appropriate credit, provide a link to the license, and indicate if changes were made and if they remix, transform, or build upon the material, they must distribute contributions under the same license as the original.



