
Enhancement of Speech for Hearing Aid Applications Integrating Adaptive Compressive Sensing with Noise Estimation Based Adaptive Gain
Keywords:
Compressive sensing, customized hearing loss, hearing aid, speech enhancementAbstract
Hearing aids provide the necessary amplification for successful rehabilitation of hearing-impaired persons. It becomes very challenging for hearing aid devices to attain close to normal hearing. This research suggests a method for improving communication for hearing-impaired people utilizing a combination of three strategies: noise estimation based integrated based gain function, adapted compressive sensing, and listener preference-based customization gain function. Use of integrated gain function and adapted compressive sensing helps to reduce the noise distortion. Use of the customization gain function allows for enhancing the noise-removed speech to the comfort level of the listener. It is achieved by shaping the frequency and amplitude of signal. The overall objective is to enhance quality (noise suppression) and intelligibility (perception) of speech. Performance of proposed solution is tested against noise at various SNR. Results are compared with existing works to established speech quality metrics. The proposed solution is able to attain about 40% improvement in noise quality and 70% reduction in processing time compared to existing works.
Downloads
References
World Health Organization. Report of the International Workshop on Primary Ear & Hearing Care; 14 March, 2018. p. 1-19. Available from: http://www.who.int/pbd/deafness/activities/en/capetown_final_report.pdf. [Last accessed on 2018 Apr 15; Last updated on 2018 Apr 15].
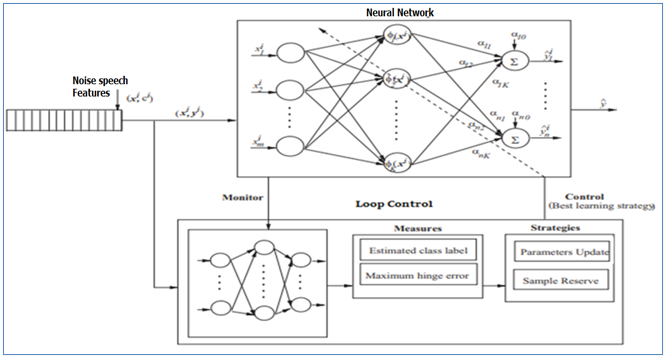
HANECHE, Houria&Boudraa, Bachir& Ouahabi, A. (2018). Speech Enhancement Using Compressed Sensing-based method. 1-6. 10.1109/CISTEM.2018.8613609.
G. S. Bhat, N. Shankar, C. K. A. Reddy and I. M. S. Panahi, "A Real-Time Convolutional Neural Network Based Speech Enhancement for Hearing Impaired Listeners Using Smartphone," in IEEE Access, vol. 7, pp. 78421-78433, 2019, doi: 10.1109/ACCESS.2019.2922370.
I. M. Panahi, C. K. A. Reddy and L. Thibodeau, "Noise suppression and speech enhancement for hearing aid applications using smartphones," 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, 2017, pp. 1890-1894, doi: 10.1109/ACSSC.2017.8335692.
Z. Zhang, Y. Shen and D. S. Williamson, "Objective Comparison of Speech Enhancement Algorithms with Hearing Loss Simulation," ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, United Kingdom, 2019, pp. 6845-6849, doi: 10.1109/ICASSP.2019.8683040.
Shankar, Nikhil &Shreedhar Bhat, Gautam & Reddy, Chandan & Panahi, Issa. (2018). Noise dependent coherence-super Gaussian based dual microphone speech enhancement for hearing aid application using smartphone. The Journal of the Acoustical Society of America. 143. 1806-1807. 10.1121/1.5035916.
Goehring, Tobias &Bolner, Federico & Monaghan, Jessica & van Dijk, Bas &Zarowski, Andrzej &Bleeck, Stefan. (2016). Speech enhancement based on neural networks improves speech intelligibility in noise for cochlear implant users. Hearing Research. 344. 10.1016/j.heares.2016.11.012.
W. Xue, A. H. Moore, M. Brookes, and P. A. Naylor. Multichannel Kalman filtering for speech enhancement. In Proc. IEEE Intl Conf. Acoustics, Speech and Signal Processing, Calgary, Canada, Apr. 2018.
N. Tiwari and P. C. Pandey, "Speech Enhancement Using Noise Estimation With Dynamic Quantile Tracking," in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 12, pp. 2301-2312, Dec. 2019, doi: 10.1109/TASLP.2019.2945485.
Y. Zhao, Z. Wang and D. Wang, "A two-stage algorithm for noisy and reverberant speech enhancement," 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, 2017, pp. 5580-5584, doi: 10.1109/ICASSP.2017.7953224.
Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee, “A regression approach to speech enhancement based on deep neural networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, pp. 7–19, 2015.
Y. Zhao, D. L. Wang, I. Merks, and T. Zhang, “DNN-based enhancement of noisy and reverberant speech,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 6525–6529
J. Chen, Y. Wang, S. E. Yoho, D. L. Wang, and E. W. Healy, “Largescale training to increase speech intelligibility for hearing-impaired listeners in novel noises,” The Journal of the Acoustical Society of America, vol. 139, pp. 2604–2612, 2016
G. S. Bhat, N. Shankar, C. K. A. Reddy, and I. M. S. Panahi, ‘‘Formant frequency-based speech enhancement technique to improve intelligibility for hearing aid users with smartphone as an assistive device,’’ in Proc. IEEE Healthcare Innov. Point Care Technol. (HI-POCT), Bethesda, MD, USA, Nov. 2017, pp. 32–35
C. K. A. Reddy, N. Shankar, G. S. Bhat, R. Charan, and I. Panahi, ‘‘An individualized super-Gaussian single microphone speech enhancement for hearing aid users with smartphone as an assistive device,’’ in IEEE Signal Process. Lett., vol. 24, no. 11, pp. 1601–1605, Nov. 2017.
E. W. Healy, S. E. Yoho, J. Chen, Y. Wang, and D. Wang, ‘‘An algorithm to increase speech intelligibility for hearing-impaired listeners in novel segments of the same noise type,’’ J. Acoust. Soc. Amer., vol. 138, no. 3, pp. 1660–1669, 2015
Y. Xu, J. Du, L.-R. Dai, and C.-H. Lee, ‘‘Dynamic noise aware training for speech enhancement based on deep neural networks,’’ in Proc. 15th Annu. Conf. Int. Speech Commun. Assoc., 2014, pp. 1–5
Y. Xu, J. Du, Z. Huang, L. R. Dai, and C. H. Lee, ‘‘Multi-objective learning and mask-based post-processing for deep neural network based speech enhancement,’’ in Proc. Interspeech, 2015, pp. 1508–1512
Ranjan, A. ., Yadav, R. K. ., & Tewari, G. . (2023). Study And Modeling of Question Answer System Using Deep Learning Technique of AI. International Journal on Recent and Innovation Trends in Computing and Communication, 11(2), 01–04. https://doi.org/10.17762/ijritcc.v11i2.6103
Q. Wang, J. Du, L.-R. Dai, and C.-H. Lee, ‘‘A multiobjective learning and ensembling approach to high-performance speech enhancement with compact neural network architectures,’’ in IEEE/ACM Trans. Audio, Speech, Language Process., vol. 26, no. 7, pp. 1185–1197, Jul. 2018.
C. K. A. Reddy, Y. Hao, and I. Panahi, ‘‘Two microphones spectralcoherence based speech enhancement for hearing aids using smartphone as an assistive device,’’ in Proc. IEEE Int. Conf. Eng. Med. Biol. Soc., Oct. 2016, pp. 3670–3673
Reddy, C.K.A, Ganguly A., Panahi, I., “ICA based single microphone blind speech separation technique using non-linear estimation of speech”, IEEE Inter. Conf. Acous. Speech,, Sig. Proc. (ICASSP), 2017, pp: 5570 – 5574.
P. Scalart and J. Vieira Filho, “Speech enhancement based on a priori signal to noise estimation,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., Atlanta, GA, May 1996, vol. 2, pp. 629–632.
M.S. ArunSankar,P.S.Sathidevi,"A scalable speech coding scheme using compressive sensing and orthogonal mapping based vector quantization",Heliyon,May,2019
A. Ravelomanantsoa, H. Rabah, A. Rouane, Compressed sensing: a simple deterministic measurement matrix and a fast recovery algorithm, IEEE Trans. Instrum. Meas. 64 (12) (2015) 3405–3413
https://ecs.utdallas.edu/loizou/speech/noizeus/
K. Zaman, S. S. Maghdid, H. Afridi, S. Ullah and M. Zohaib, "Enhancement of Speech Signals for Hearing Aid Devices using Digital Signal Processing," 2020 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), 2020, pp. 1-7, doi: 10.1109/ISMSIT50672.2020.9255299.
Johnson, M., Williams, P., González, M., Hernandez, M., & Muñoz, S. Applying Machine Learning in Engineering Management: Challenges and Opportunities. Kuwait Journal of Machine Learning, 1(1). Retrieved from http://kuwaitjournals.com/index.php/kjml/article/view/90
Garg S, Chadha S, Malhotra S, Agarwal AK. Deafness: burden, prevention and control in India. Natl Med J India. 2009 Mar-Apr;22(2):79-81. PMID: 19852345
Hassager, Henrik & Wiinberg, Alan & Dau, Torsten. (2017). Effects of hearing-aid dynamic range compression on spatial perception in a reverberant environment. The Journal of the Acoustical Society of America. 141. 2556-2568. 10.1121/1.4979783.
Dobie RA, Van Hemel S, editors. Hearing Loss: Determining Eligibility for Social Security Benefits. Washington (DC): National Academies Press (US); 2004. 2, Basics of Sound, the Ear, and Hearing.
Andrade, Adriana Neves de, Iorio, Maria Cecilia Martinelli, & Gil, Daniela. (2016). Speech recognition in individuals with sensorineural hearing loss. Brazilian Journal of Otorhinolaryngology, 82(3), 334-340.
A. W. Rix, J. G. Beerends, M. P. Hollier and A. P. Hekstra, "Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs," 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.01CH37221), 2001, pp. 749-752 vol.2,
Salovarda, M. & Bolkovac, I. & Domitrović, Hrvoje. (2005). Estimating Perceptual Audio System Quality Using PEAQ Algorithm. 1 - 4. 10.1109/ICECOM.2005.205017.
Anis Ben Aicha and Sofia Ben Jebara. 2012. Perceptual speech quality measures separating speech distortion and additive noise degradations. Speech Commun. 54, 4 (May, 2012), 517–528.
Gouyon F., Pachet F., Delerue O. (2000),On the Use of Zero-crossing Rate for an Application of Classification of Percussive Sounds, in Proceedings of the COST G-6 Conference on Digital Audio Effects (DAFX-00 - DAFX-06), Verona, Italy, December 7–9, 2000.
de Lara JRC. A method of automatic speaker recognition using cepstral features and vectorial quantization. In: Iberoamerican Congress on Pattern Recognition. Berlin, Heidelberg: Springer; 2005. pp. 146-153
C. Z. Tang and H. K. Kwan, "Multilayer feedforward neural networks with single powers-of-two weights," in IEEE Transactions on Signal Processing, vol. 41, no. 8, pp. 2724-2727, Aug. 1993, doi: 10.1109/78.229903.
Mahmmod, Basheera & H. Abdulhussain, Sadiq & Naser, Marwah & Abdulhasan, Muntadher & Mustafina, Jamila. (2021). Speech Enhancement Algorithm Based on a Hybrid Estimator. IOP Conference Series: Materials Science and Engineering. 1090. 10.1088/1757-899X/1090/1/012102.
B. M. Mahmmod, A. R. Ramli, T. Baker, F. Al-Obeidat, S. H. Abdulhussain and W. A. Jassim, "Speech Enhancement Algorithm Based on Super-Gaussian Modeling and Orthogonal Polynomials," in IEEE Access, vol. 7, pp. 103485-103504, 2019
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2023 Hrishikesh B. Vanjari , Sheetal U. Bhandari, Mahesh T. Kolte

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
All papers should be submitted electronically. All submitted manuscripts must be original work that is not under submission at another journal or under consideration for publication in another form, such as a monograph or chapter of a book. Authors of submitted papers are obligated not to submit their paper for publication elsewhere until an editorial decision is rendered on their submission. Further, authors of accepted papers are prohibited from publishing the results in other publications that appear before the paper is published in the Journal unless they receive approval for doing so from the Editor-In-Chief.
IJISAE open access articles are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. This license lets the audience to give appropriate credit, provide a link to the license, and indicate if changes were made and if they remix, transform, or build upon the material, they must distribute contributions under the same license as the original.



