
Sentiment Analysis of Customer Reviews using Pre-trained Language Models
Keywords:
Sentiment analysis, customer reviews, pre-trained language models, BERT, XLNet, Electra, Sentiment140 dataset, transformer models, fine-tuning.Abstract
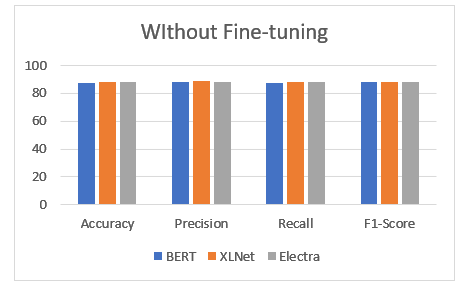
Due to the increasing number of reviews, it has become more important for businesses to analyze their customer's sentiments. This paper presents a framework that uses pre-trained language models such as BERT, XLNet, and Electra to analyze these sentiments. The framework is based on the Sentiment140 dataset which contains over 1.6 million tweets with tags. This collection of sentiments allows us to perform an evaluation of the models' performance. The goal of this paper is to analyze the effectiveness of these models in categorizing and understanding the sentiments in customer reviews. BERT, for instance, has demonstrated exceptional performance in various tasks related to natural language processing. Another model that is transformer-based is XLNet, which adds more capabilities by utilizing permutation-based learning. On the other hand, the new generation of model, known as Electra, focuses on the generator discriminator learning. Through the incorporation of these models, we can leverage the contextual understanding of the sentiments in the customer reviews. In this paper, we thoroughly examine the performance of the different models in the framework for sentiment analysis. We tested their precision, recall, F1-score, and accuracy in identifying and categorizing the sentiments in customer reviews. We also discuss the impact of adjusting the models on the task, as well as the tradeoffs between performance gains and computational resources. The findings of the study provided valuable information on the utilization of pre-trained models for analyzing customer reviews. We analyzed the performance of the different models BERT, XLNet, Electra, and BERT, revealing their weaknesses and strengths. This helps businesses identify the best model for their sentiment analysis needs. The study's findings have contributed to the advancement of sentiment analysis and natural language processing. It offers valuable recommendations that will aid in the future research efforts.
Downloads
References
K. Ahmed, N. El Tazi, and A. H. Hossny, “Sentiment Analysis over Social Networks: An Overview,” Proc. - 2015 IEEE Int. Conf. Syst. Man, Cybern. SMC 2015, pp. 2174–2179, 2016, doi: 10.1109/SMC.2015.380.
S. A. Bahrainian and A. Dengel, “Sentiment analysis and summarization of twitter data,” Proc. - 16th IEEE Int. Conf. Comput. Sci. Eng. CSE 2013, pp. 227–234, 2013, doi: 10.1109/CSE.2013.44.
E. Cambria, “An introduction to concept-level sentiment analysis,” Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), vol. 8266 LNAI, no. PART 2, pp. 478–483, 2013, doi: 10.1007/978-3-642-45111-9_41.
S. Gupta and S. K. Gupta, “Natural language processing in mining unstructured data from software repositories: a review,” Sadhana - Acad. Proc. Eng. Sci., vol. 44, no. 12, pp. 1–17, 2019, doi: 10.1007/s12046-019-1223-9.
A. Kumar and T. M. Sebastian, “Sentiment Analysis: A Perspective on its Past, Present and Future,” Int. J. Intell. Syst. Appl., vol. 4, no. 10, pp. 1–14, 2012, doi: 10.5815/ijisa.2012.10.01.
G. Vinodhini and R. Chandrasekaran, “Sentiment Analysis and Opinion Mining : A Survey International Journal of Advanced Research in Sentiment Analysis and Opinion Mining : A Survey,” Int. J. Adv. Res. Comput. Sci. Softw. Eng., vol. 2, no. 6, pp. 283–292, 2012.
J. Serrano-Guerrero, J. A. Olivas, F. P. Romero, and E. Herrera-Viedma, “Sentiment analysis: A review and comparative analysis of web services,” Inf. Sci. (Ny)., vol. 311, pp. 18–38, 2015, doi: 10.1016/j.ins.2015.03.040.
V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter,” pp. 2–6, 2019, [Online]. Available: http://arxiv.org/abs/1910.01108.
[9] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “ALBERT: A Lite BERT for Self-supervised Learning of Language Representations,” pp. 1–17, 2019, [Online]. Available: http://arxiv.org/abs/1909.11942.
Mr. Vaishali Sarangpure. (2014). CUP and DISC OPTIC Segmentation Using Optimized Superpixel Classification for Glaucoma Screening. International Journal of New Practices in Management and Engineering, 3(03), 07 - 11. Retrieved from http://ijnpme.org/index.php/IJNPME/article/view/30
Y. Liu et al., “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” no. 1, 2019, [Online]. Available: http://arxiv.org/abs/1907.11692.
E. Lloret and M. Palomar, “Text summarisation in progress: A literature review,” Artif. Intell. Rev., vol. 37, no. 1, pp. 1–41, 2012, doi: 10.1007/s10462-011-9216-z.
Pasha, M. J. ., Rao, C. R. S. ., Geetha, A. ., Fernandez, T. F. ., & Bhargavi, Y. K. . (2023). A VOS analysis of LSTM Learners Classification for Recommendation System. International Journal on Recent and Innovation Trends in Computing and Communication, 11(2s), 179–187. https://doi.org/10.17762/ijritcc.v11i2s.6043
C. S. Yadav and A. Sharan, “Hybrid Approach for Single Text Document Summarization Using Statistical and Sentiment Features,” Int. J. Inf. Retr. Res., vol. 5, no. 4, pp. 46–70, 2015, doi: 10.4018/ijirr.2015100104.
R. K. Amplayo and M. Song, “An adaptable fine-grained sentiment analysis for summarization of multiple short online reviews,” Data Knowl. Eng., vol. 110, no. May, pp. 54–67, 2017, doi: 10.1016/j.datak.2017.03.009.
M. Gambhir and V. Gupta, “Recent automatic text summarization techniques: a survey,” Artif. Intell. Rev., vol. 47, no. 1, pp. 1–66, 2017, doi: 10.1007/s10462-016-9475-9.
Q. A. Al-Radaideh and D. Q. Bataineh, “A Hybrid Approach for Arabic Text Summarization Using Domain Knowledge and Genetic Algorithms,” Cognit. Comput., vol. 10, no. 4, pp. 651–669, 2018, doi: 10.1007/s12559-018-9547-z.
A. Rosewelt and A. Renjit, “Semantic analysis-based relevant data retrieval model using feature selection, summarization and CNN,” Soft Comput., vol. 24, no. 22, pp. 16983–17000, 2020, doi: 10.1007/s00500-020-04990-w.
M. Yang, Q. Qu, Y. Shen, K. Lei, and J. Zhu, “Cross-domain aspect/sentiment-aware abstractive review summarization by combining topic modeling and deep reinforcement learning,” Neural Comput. Appl., vol. 32, no. 11, pp. 6421–6433, 2020, doi: 10.1007/s00521-018-3825-2.
O. Habimana, Y. Li, R. Li, X. Gu, and G. Yu, “Sentiment analysis using deep learning approaches: an overview,” Sci. China Inf. Sci., vol. 63, no. 1, pp. 1–36, 2020, doi: 10.1007/s11432-018-9941-6.
S. Contreras Hernández, M. P. Tzili Cruz, J. M. Espínola Sánchez, and A. Pérez Tzili, “Deep Learning Model for COVID-19 Sentiment Analysis on Twitter,” New Gener. Comput., vol. 41, no. 2, pp. 189–212, 2023, doi: 10.1007/s00354-023-00209-2.
A. Mewada and R. K. Dewang, “SA-ASBA: a hybrid model for aspect-based sentiment analysis using synthetic attention in pre-trained language BERT model with extreme gradient boosting,” J. Supercomput., vol. 79, no. 5, pp. 5516–5551, 2023, doi: 10.1007/s11227-022-04881-x.
Mrs. Leena Rathi. (2014). Ancient Vedic Multiplication Based Optimized High Speed Arithmetic Logic . International Journal of New Practices in Management and Engineering, 3(03), 01 - 06. Retrieved from http://ijnpme.org/index.php/IJNPME/article/view/29
Q. Yong, C. Chen, Z. Wang, R. Xiao, and H. Tang, “SGPT: Semantic graphs based pre-training for aspect-based sentiment analysis,” World Wide Web, 2023, doi: 10.1007/s11280-022-01123-1.
“Sentiment Analysis - Twitter Dataset _ Kaggle.” .
K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, “ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators,” pp. 1–18, 2020, [Online]. Available: http://arxiv.org/abs/2003.10555.
J. Devlin, M. W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” NAACL HLT 2019 - 2019 Conf. North Am. Chapter Assoc. Comput. Linguist. Hum. Lang. Technol. - Proc. Conf., vol. 1, no. Mlm, pp. 4171–4186, 2019.
Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. Salakhutdinov, and Q. V. Le, “XLNet: Generalized autoregressive pretraining for language understanding,” Adv. Neural Inf. Process. Syst., vol. 32, no. NeurIPS, pp. 1–11, 2019.
Downloads
Published
How to Cite
Issue
Section
License

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
All papers should be submitted electronically. All submitted manuscripts must be original work that is not under submission at another journal or under consideration for publication in another form, such as a monograph or chapter of a book. Authors of submitted papers are obligated not to submit their paper for publication elsewhere until an editorial decision is rendered on their submission. Further, authors of accepted papers are prohibited from publishing the results in other publications that appear before the paper is published in the Journal unless they receive approval for doing so from the Editor-In-Chief.
IJISAE open access articles are licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. This license lets the audience to give appropriate credit, provide a link to the license, and indicate if changes were made and if they remix, transform, or build upon the material, they must distribute contributions under the same license as the original.



